TP001: Cloud DR
Cloud Disaster Recovery (DR)
Author: Darren Lester
Last Updated: 05/07/2022
Page Overview
- Content
- Solution
- Rationale
- Implications
- Example Use Cases
- Anti-Patterns
- Terminology
- Other Useful Links
Context
Within the LZiaB environment, it is expected that your service’s availability requirements are generally met through the use of high availability patterns, such as:
- Using regional (i.e. multi-zone) resources, rather than zonal (where possible).
- Resources that can be deployed regionally include (for example): regional managed instance groups, regional load balancers, regional persistent disks, regional external IP addresses, Google Kubernetes Engine (GKE), Cloud Storage, Cloud Datastore, etc.
- Zonal resources include (for example): compute instances, zonal persistent disks.
- (Note that some Google cloud-native resources are global, such as VPCs, Cloud Firewalls, and Pub/Sub.)
- Using managed instance groups, fronted with a load balancer, when using GCE instances; i.e. to mitigate the risk of a zone outage.
However, even regional resources are not completely immune to significant disaster events that impact a geographic region. Consider events such as: major earthquakes, floods, acts of terrorism, or even a regional outage of a cloud provider.
Consequently, where our applications are sufficiently critical (as driven by RTOs and RPOs) we have need of disaster recovery solutions that can be used in the event of a prolonged outage of an entire region.
Solution
Our preferred approach in LZiaB is to execute DR using infrastructure-on-demand, coupled with automation through infrastructure-as-code.
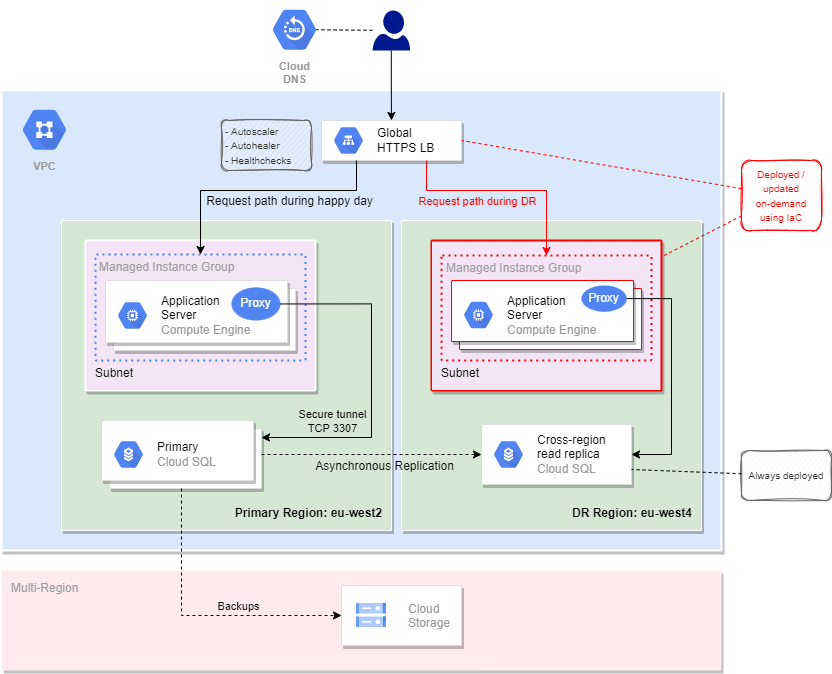
Key tenets of this approach:
- Your solution will have a primary production environment, hosted in our London region. This region has resilient private connectivity to our data centres through interconnects.
- Your solution will have a standby environment, hosted in our DR region. This region also has resilient private connectivity to our data centres through interconnects.
- Your primary production environment contains a full stack of your required infrastructure and services.
- This stack will have been created using Terraform IaC, and deployed using the LZiaB build pipeline, through your service account.
- Furthermore, in the normal (happy day) scenario, all traffic (e.g. user / client requests) is directed to this environment.
- Your standby environment will typically have very little infrastructure deployed. (Exceptions to be covered later.)
- In the event of a regional disaster:
- The disaster event will be detected by appropriate measures. (I.e. appropriate monitoring and alerting.)
- This event will trigger your DR decision process. You can fully automate this process, but tenants often prefer to include some manual decision points.
- Your DR process will use your IaC to deploy your infrastructure and services to the standby region, on-demand. This Terraform process is not typically expected to require more than a few minutes to complete. (And thus can typically achieve the RTOs demanded by our most critical applications.)
- Note that the on-demand infrastructure is indicated in the diagram using red borders.
- For applications requiring external access and therefore using external IP addresses:
- We will use a Global HTTPS load balancer.
- In the happy day scenario, this LB points only to the primary managed instance group backend.
- In the DR scenario, IaC reconfigures the LB to use the standby managed instance group as its backend.
- For applications requiring only internal access and therefore using internal IP addresses:
- We will use regional internal load balancers instead.
- In the happy day scenario, DNS points all requests to a primary regional internal LB.
- In the DR scenario, a new LB is built in the standby region, on-demand, and DNS is updated to point to this LB.
- Cloud SQL is an example of a service where on-demand deployment is not feasible. Rationale for this:
- Depending on your RPO, it is likely that you will have a need to continuously replicate data from your primary database to your standby database.
- Alternatively, backups could be used, but these will typically achieve a much longer RPO, and furthermore, restoration from backups takes a long time. Thus, a longer RTO is also expected.
- Cloud Storage is shown as an example of a resource that is already multi-regional. Consequently, there is no need to deploy DR Cloud Storage buckets on-demand, in this pattern.
TODO: How to update DNS? What is the propagation delay? Do we want to pre-provision static (reserved) internal IP addresses?
Rationale
Pros for this pattern
- It can achieve the RTOs and RPOs of our most critical systems. (Assuming we leverage IaC.)
- It is relatively cheap, since DR infrastructure is only deployed when needed. Thus, we avoid wasting spend on pay-as-you-go infrastructure that is not being used.
- It is a relatively simple design, and users / clients will only ever expect to deal with one environment or the other. (Of course, this is hidden from the user.) The failure complexities and confusion that can arise from a cross-regional active/active architecture are avoided.
Alternative Pattern: Active/Hot-Standby
The Active/(Hot/Warm)-Standby pattern is our preferred pattern for on-premises workloads.
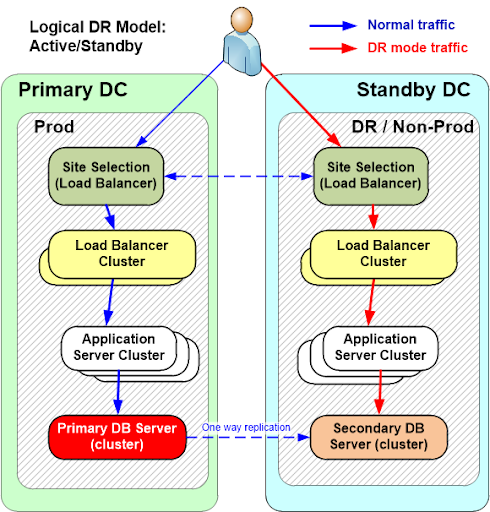
Key tenets of this pattern:
- A full stack of infrastructure and services is deployed to our primary data centre.
- A replica of this full stack is deployed to our DR data centre. It is always running, and continually maintained and patched; just like the primary stack.
- A “site selection” load balancer can send traffic to either the primary or DR stack.
- However, in the normal happy day scenario, requests are only sent to the primary stack. The DR stack is doing no real work, except for the receiving of any data replication (e.g. from a primary database).
- In the event of DR, the site selection load balancer redirects requests to the standby site.
Rationale for this pattern on-premises:
- This pattern is easily able to achieve the RTOs and RPOs of our most critical systems. It is, for example, possible to automate the failover of both the load balancer, and the promotion of the standby database, such that DR can be invoked within a few minutes of a DR event being detected.
- At-a-glance, this pattern may look expensive and wasteful, on account of deploying a generally unused duplicate stack in the DR site.
- However, we also have need for non-production environments, e.g. for development, testing, QA, performance testing, etc. And by leveraging the virtualisation capabilities of our VMware-based on-premises infrastructure, we can deploy these non-production environments to the same hardware where we run the DR environments. Thus, our DR environments and non-prod environments share the same physical hardware.
- Furthermore, through the automated intelligence of our virtualisation platform, it is possible to ensure that the DR environment is given priority over any and all non-production environments, in the event that the DR stack is being used. I.e. in response to a DR event.
- Thus, the active/standby model is actually a very cost-effective way to leverage our on-premises infrastructure, and to continuously ensure good utilisation of our assets.
- Building full environments on-premises is far more time consuming and far less automated than in the cloud. Consequently, on-demand infrastructure provisioning is not able to meet the RTOs of our most critical systems, for on-premises systems.
Rationale for avoiding this pattern in LZiaB:
- A key difference between our on-premises infrastructure and our cloud platform is that in the latter, we only pay for what we use.
- Furthermore, in the cloud (unlike our on-premises infrastructure) there is no value - and no cost-effective ability - to share non-production and DR environments on the same physical hardware.
- Consequently, our preferred approach in LZiaB is to only run environments (and thus pay for them) when needed.
- And finally: our automated full stack provisioning in cloud is much faster than what we can achieve on-premises.
Implications
- We must ensure that our IaC is able to deploy to our DR region.
- We must be mindful of any need to replicate data. Consequently, we will have a frequent requirement to deploy replicated databases that exist outside of the on-demand infrastructure. The promotion of a standby database to a production database may require manual steps. And, as with any DR scenario that promotes a standby database, we must ensure there is a way to switch back to using the original primary.
- We must be mindful of any latency implications of operating out of a different region.
Example Use Cases
- App 1
- App 2
Note that any existing implementations of the pattern may change over time.
Anti-Patterns
TBC.
Terminology
| Term | Description |
|---|---|
| Availability | A quantifiable measure of how reliable a service is, in terms of how much downtime can be tolerated over a given period. Often, availability is expressed in terms of “nines”, which is a shorthand for a percentage of time available. E.g. 4 nines means 99.99%. Availability ‘nines’ should explicitly exclude planned/allowed maintenance windows. Availability is typically assured through high availability technologies, redundancy, and avoidance of any single points of failure. |
| Zone | The most granular level of deployment of a GCP resource. In GCP, a zone is typically implemented as one or more data centres in close proximity. (I.e. within a few km.) A zone is considered a single independent failure domain within a region. |
| Region | Independent geographic areas; typically sub-continents, composed of (typically) three or four zones. Regional resources are available across all zones in a given region, and will typically have higher availability SLAs than zonal resources. Google regional resources typically have a 99.99% availability goal. |
| RPO | Recovery Point Objective (Capability) - maximum allowed duration of data loss, as a result of a disaster event or major unplanned outage. |
| RTO | Recovery Time Objective (Capability) - ie. maximum tolerable duration of outage, following a disaster event or major unplanned outage. |
Other Useful Links
- Architecting for DR in Google Cloud
- Google Cloud DR Building Blocks
- DR Scenarios for Data on Google Cloud
- Availability Tiers - including RTOs and RPOs